The Challenge: Making Sense of a Pandemic's Worth of Research
When COVID-19 hit, the scientific community responded with unprecedented speed and collaboration. Researchers worldwide published thousands of papers monthly, creating a massive corpus of knowledge that could help save lives. But here's the problem: how do you analyze 200,000+ research papers efficiently?
The CORD-19 dataset became the definitive collection of COVID-19 research literature, containing full-text academic papers, metadata, and structured content. While this treasure trove of information held immense potential for insights, processing it required serious computational firepower.
That's where this distributed analysis project comes in.
The Solution: Distributed Computing Meets Text Analysis
This is a project I made with my collegues at UNIPD, in which we designed and implemented a distributed computing system using Dask to tackle this massive dataset across multiple machines. The goal was to extract meaningful insights about research trends, geographic collaboration patterns, and institutional contributions to COVID-19 research.
Architecture Overview
The system consists of three main components:
SSH Cluster Setup
- Multiple machines connected via SSH for distributed computing
- Dynamic scaling based on workload requirements
- Fault-tolerant task distribution across worker nodes
NFS Shared Storage
- Centralized file system accessible by all cluster nodes
- Efficient data sharing without redundant transfers
- Seamless access to the massive JSON dataset
Distributed Processing Pipeline
- MapReduce-style word counting across all documents
- Geographic analysis of research contributions
- Institutional impact analysis
- Semantic similarity matching using word embeddings
Technical Deep Dive
1. Distributed Word Counting at Scale
Processing text from 200,000+ papers requires efficient distributed computing. I implemented a MapReduce approach using Dask:
# Distributed word counting across the cluster
json_files = db.read_text('/shared/cord19/document_parses/*.json')
word_counts = json_files.map_partitions(extract_words).frequencies()
top_words = word_counts.topk(1000).compute()The beauty of this approach is that each worker node processes its assigned partition of files independently, then the results are efficiently aggregated.
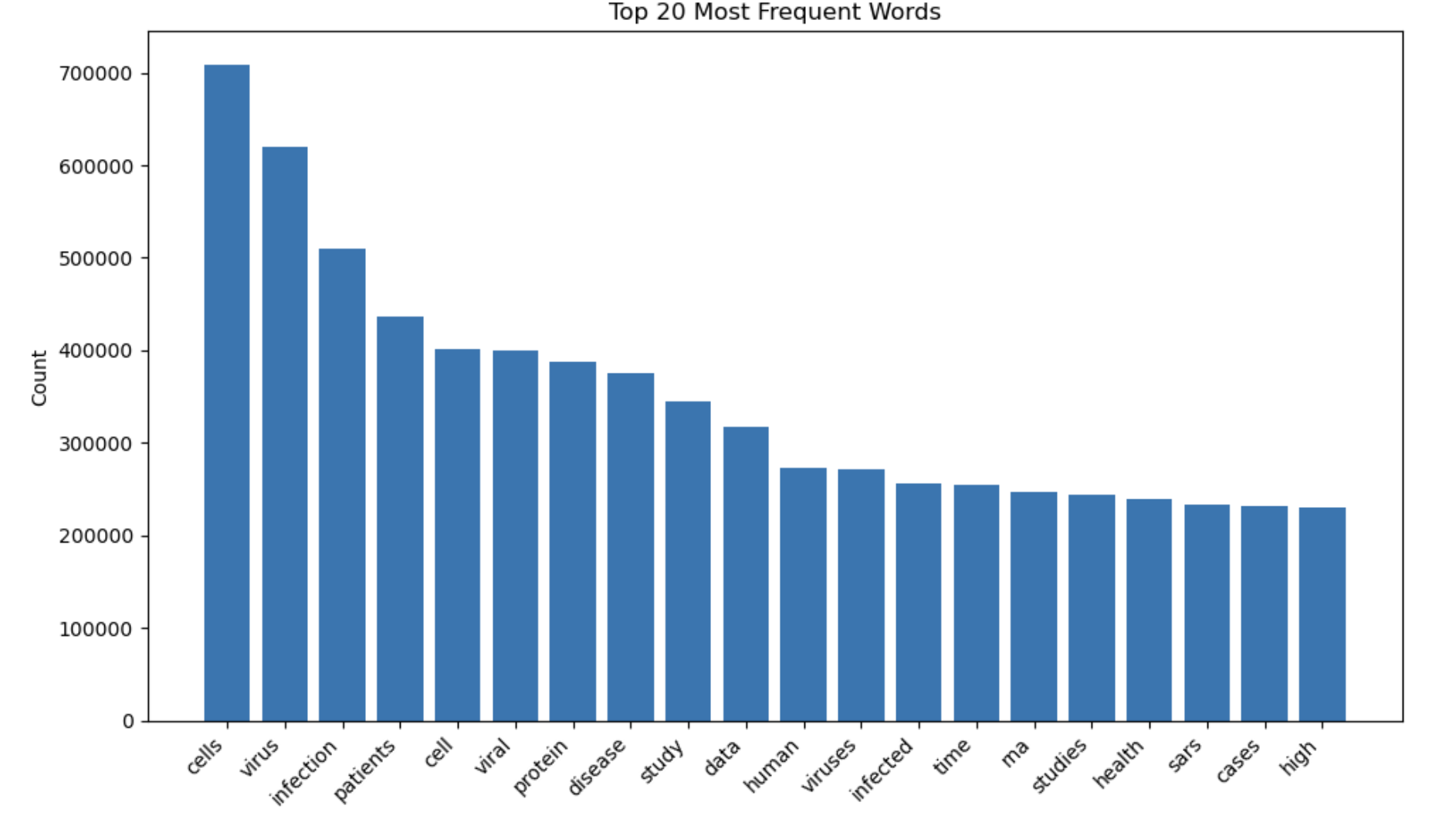
The following are the results, where we can view the most used words in the research.
2. Geographic Research Mapping
Understanding where COVID-19 research was happening globally required parsing institutional affiliations and geographic metadata:
- Pattern Recognition: Extracted country information from author affiliations
- Data Normalization: Standardized geographic references across different formats
- Distributed Processing: Leveraged cluster computing to process affiliations in parallel
3. Institutional Impact Analysis
Identifying leading research institutions provided insights into global research capacity:
- Entity Extraction: Parsed institutional names from paper metadata
- Frequency Analysis: Ranked institutions by research output
- Collaboration Networks: Analyzed co-authorship patterns across institutions
4. Semantic Similarity Engine
Perhaps the most exciting feature was building a semantic search system:
# Word embeddings for title similarity
model = Word2Vec(titles, vector_size=100, window=5, min_count=1)
similarity_scores = cosine_similarity(query_embedding, title_embeddings)This allows researchers to find papers with similar themes, even when they don't share exact keywords.
Key Results & Insights
The distributed analysis revealed fascinating patterns:
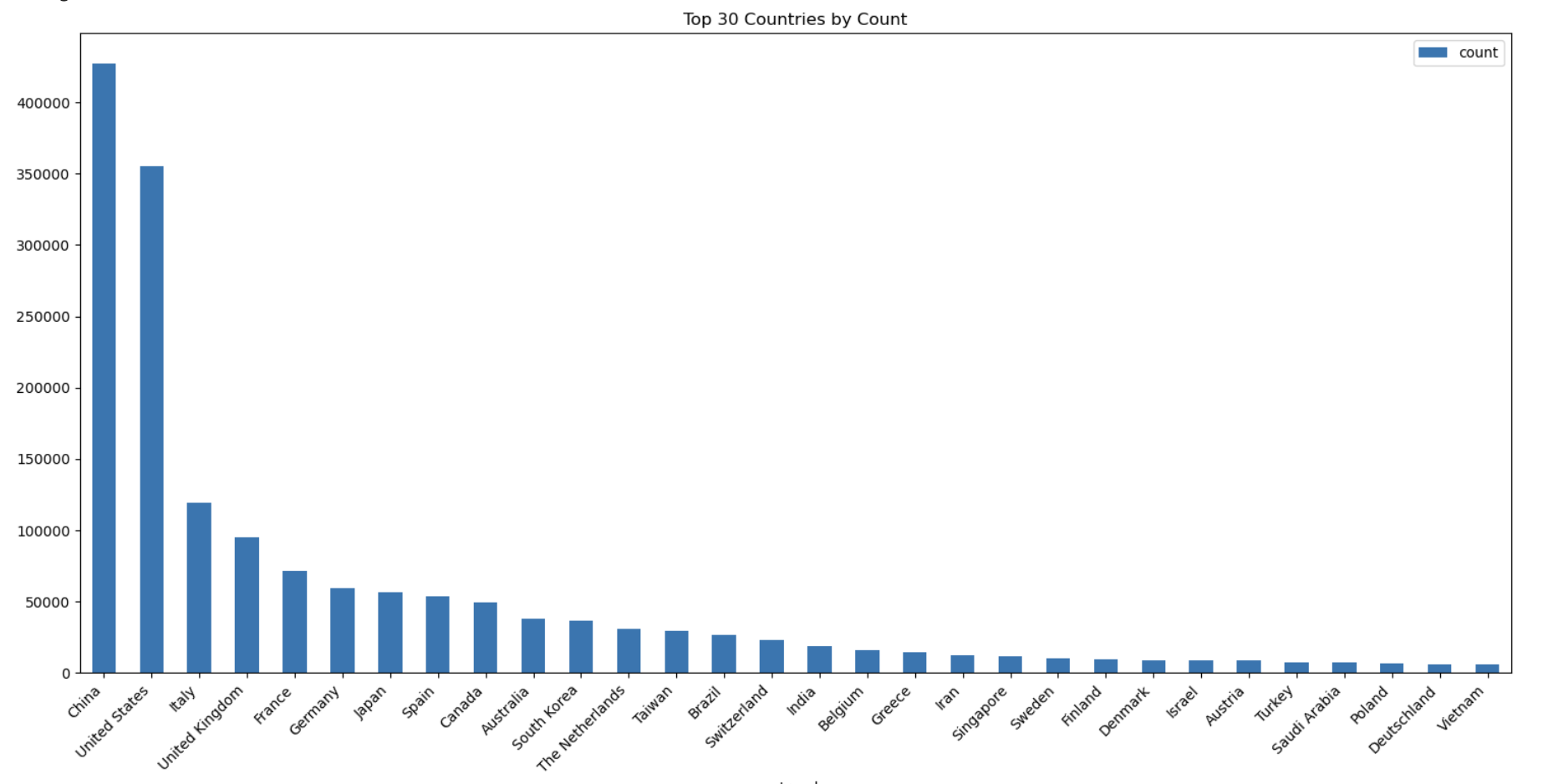
Global Research Distribution
- Identified leading countries in COVID-19 research output
- Revealed international collaboration patterns
- Tracked research momentum across different regions
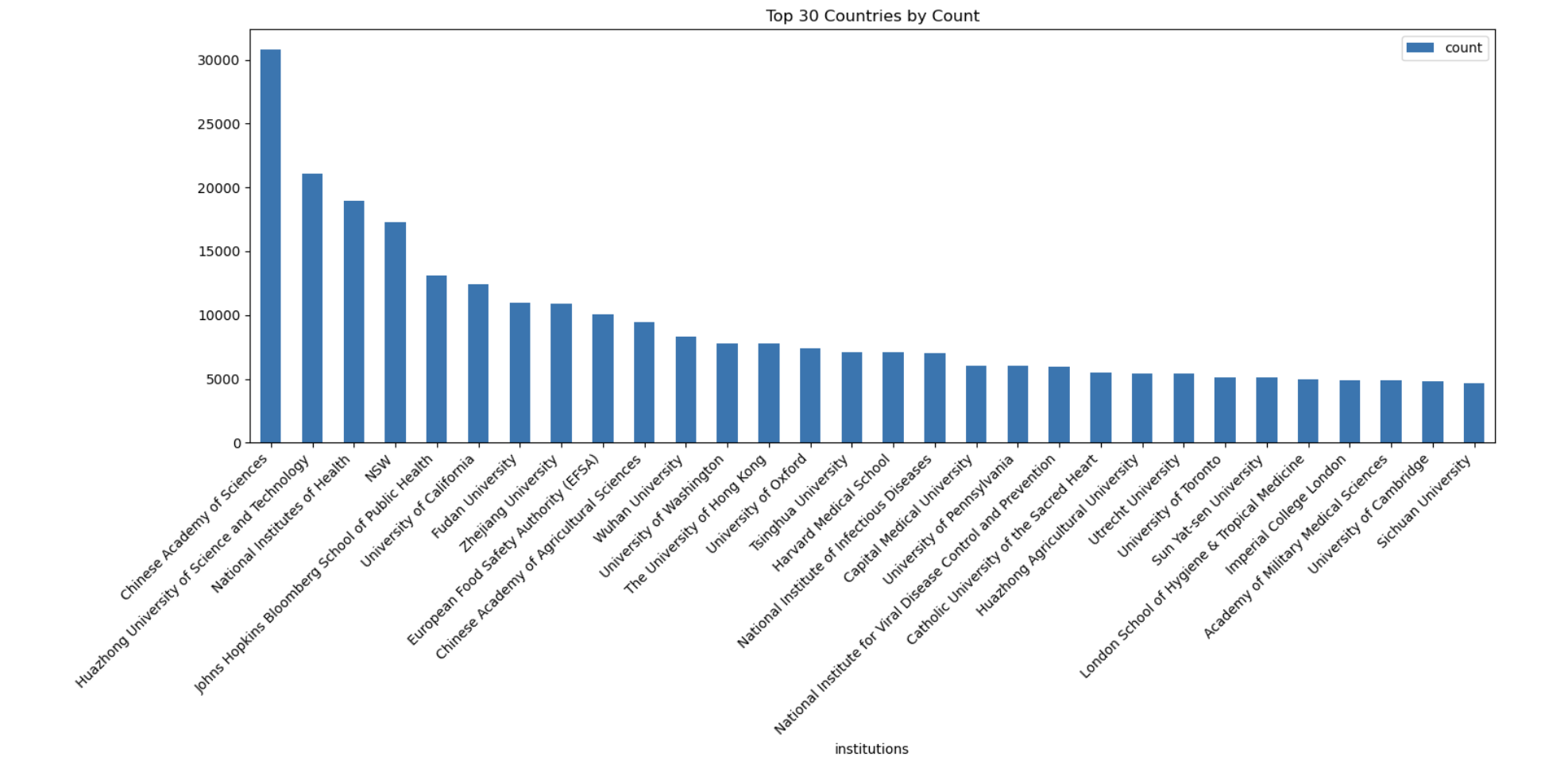
Institutional Powerhouses
- Ranked universities and research institutions by contribution
- Analyzed specialization areas by institution
- Mapped research ecosystem relationships
Research Trends
- Most frequent terms and evolving vocabulary
- Topic clustering and thematic analysis
- Timeline analysis of research focus shifts
Technical Skills Demonstrated
This project showcases several advanced technical capabilities:
- Distributed Systems: Designed and implemented multi-machine computing clusters
- Big Data Processing: Handled datasets too large for single-machine processing
- Natural Language Processing: Applied NLP techniques to scientific literature
- System Administration: Configured SSH clusters and NFS shared storage
- Python Ecosystem: Leveraged Dask, scikit-learn, Gensim, and other libraries
- Performance Optimization: Implemented memory management and load balancing
The Impact: From Data to Discovery
This project demonstrates how distributed computing can democratize large-scale research analysis. By making it possible to process massive datasets efficiently, we can:
- Accelerate Research Discovery: Find relevant papers faster through semantic similarity
- Identify Research Gaps: Spot underexplored areas in the literature
- Track Global Collaboration: Understand how research communities connect
- Support Evidence-Based Decisions: Provide data-driven insights for policy makers
Lessons Learned
Building this distributed system taught me valuable lessons about:
- Scalability Design: How to architect systems that grow with data
- Fault Tolerance: Handling node failures in distributed environments
- Performance Tuning: Optimizing memory usage and task distribution
- Real-World Data: Managing the messiness of actual scientific datasets
Try It Yourself
The project is open source and available on GitHub. The codebase includes:
- Complete SSH cluster setup scripts
- NFS configuration guidelines
- Analysis pipelines for various research questions
- Performance optimization techniques
- Example notebooks for getting started
Whether you're interested in distributed computing, text analysis, or COVID-19 research, this project offers practical insights into building scalable data analysis systems.
What's Next?
This project opened my eyes to the power of distributed computing for research analysis. I'm excited to apply these techniques to other domains where large-scale text processing can drive insights – from legal document analysis to social media research.
Interested in distributed computing or large-scale text analysis? I'd love to discuss how these techniques could apply to your projects. Feel free to reach out or check out the complete technical implementation in the GitHub repository.
Have questions about the technical implementation or want to collaborate on similar projects? Let's connect!